Здесь будут вкратце объяснены некоторые базовые понятия, использующиеся в дальнейшем описании. Те, кто понимает термины "кодировка", "кодовая страница", Unicode, кому очевидна кодировочная разрядность известных приложений в Windows, могут смело пропустить этот раздел.
![]()
Хочется нам этого или нет, но современные компьютеры работают пока что только с числами. На экране могут быть красивые картинки и умные подсказки, удобный интерфейс и веселое музыкальное сопровождение -- но для компьютера все это является лишь обработкой чисел. Любой объект, с которым работает компьютерная программа, должен быть так или иначе представлен в виде набора чисел. Любая картинка на экране -- это длинный перечень номеров цветов точек, которые эту картинку составляют, либо список координат линий и фигур, из которых состоит рисунок. Красивая мелодия изнутри -- лишь колонка цифр, описывающих прихотливую форму колебаний воздуха, либо скучная таблица, когда и каким инструментом должна звучать каждая нота симфонии, как долго и как громко. Строки символов, составляющих документ, набранный в Ворде... Символы в компьютере также представляются в виде цифр.
Разумеется, сами по себе числа еще не несут в себе никакой смысловой информации. К ним должно быть приложено некоторое знание. Инструкция, как понимать тот или иной набор чисел. Описание того, что шестое число в последовательности картинки -- это количество использованных в ней цветов, а двадцать седьмое число в музыкальном файле -- это количество членов ряда Фурье в разложении функции первой сотни миллисекунд мелодии. К представлению текста в виде числовой последовательности это относится в такой же степени.
Процесс представления любой информации в виде чисел называется кодированием, а инструкция по пониманию кодированной информации -- способом кодирования. Обратный процесс (из чисел -- в исходную информацию) -- декодирование.
Сосредоточимся на способах кодирования текста. Первый, напрашивающийся самим собой способ -- присвоить каждой букве из алфавита языка уникальное число. Текст же записывать в виде последовательности чисел, относящихся к каждой букве. А как отделять слова? Присвоим и пробелу свое собственное число. А знаки препинания? Их тоже занумеруем. А как быть, если нужно перейти на новую строку? Возьмем еще одно число, и присвоим ему следующий смысл: если оно встретилось в последовательности кодов, в этом месте нужно перейти на другую строку. Хорошо, а как обозначить переход на курсивный текст, или смену шрифта, или буквы разного размера, или... Давайте пока остановимся, нам есть что обсуждать и из уже сказанного.
Числа, поставленные в соответствие символам при таком способе кодирования, называются кодами символов. Таким образом, мы получаем таблицу соответствия символов и их кодов. Можем, например, договориться, что буква "А" у нас имеет код 1, "а" -- 2, "Б" -- 3, "б" -- 4, и т.д. Таблица эта называется кодировкой. То есть, кодировка -- это закон, посредством которого различным символам, используемым в тексте, сопоставляются уникальные для каждого символа коды-числа, пригодные для хранения и обработки компьютером.
Что же теперь делать с этой кодировкой? Обучать ей свои программы и периферийные устройства компьютера. Можно сделать принтер так, чтобы, если на него поступает код 1, он изображал иголками букву "А", а если 3 -- букву "Б". От клавиатуры также можно добиться того, что, если мы нажимаем на клавишу "А", в компьютер посылается код 1, а если "Б" -- 3. Аналогичным образом спаяем себе схему монитора. Что будет объединять все эти устройства? То, что они работают по одной кодировке. Если, скажем, соединить клавиатуру и принтер напрямую, они оба могут даже не заботиться о понимании проходимых через них кодов. Все равно, если мы нажали на клавиатуре "А", именно "А" и напечатает принтер -- ведь оба они настроены на одну кодировку.
Но это еще не все. Если Вася придумал себе одну кодировку, а Петя -- другую, пользы от этого будет немного. Ведь они не смогут свободно обмениваться текстами. Вася набрал на своей клавиатуре сочинение (получив последовательность кодов), записал его на диск (в виде последовательности-же кодов), отнес его Пете с просьбой напечатать на своем принтере -- а Петя-то не может! Потому что у него код 1 -- это "пробел", код 2 -- это "плюс", ну а буква "А" имеет код 45. Отправляет он Васино сочинение (в виде последовательности кодов) на свой принтер -- а принтер выдает шифровку. Ибо набрано это сочинение не на Петиной клавиатуре, а на Васиной. Кодировки у них разные.
Надо бы перед печатью преобразовать Васин текст в Петину кодировку -- благо, у Пети есть компьютер, пусть он и потрудится. Надо только сообщить компьютеру, что число 1 из Васиного сочинения надо везде заменить на 45, число 3 -- на 46 и т.д. После этого уже можно будет смело отправлять сочинение на Петин принтер. Этот процесс, процесс перевода закодированного текста из одной кодировки в другую, называется перекодировкой текста, а сама программа -- перекодировщиком или конвертером (это не единственное значение).
В случае с двумя пользователями дело обстоит просто. А если их сотня миллионов? Писать 20000000000000000 программ-конвертеров? Нет. Куда проще придумать для всех пользователей одну-единственную, подходящую под нужды любого пользователя кодировку -- и заставить всех в мире пользоваться только ею. То есть, принять кодировочный стандарт. Ибо не будет каждый пользователь делать себе и монитор, и принтер. Мониторы и принтеры выпускаются серийно на заводах, причем частенько на разных. А принтера одного завода должны понимать клавиатуры другого.
Это все к вопросу, а зачем вообще нужна кодировка, зачем нужен кодировочный стандарт, и почему иногда бывает, что русские буквы текста вдруг превращаются в иероглифы и кракозябры. Очень просто, кодировки разные. Почему вдруг разные -- это уже более сложный вопрос. А почему их вообще несколько, этих кодировок, ведь ясно же, что куда удобнее одна-единственная на все случаи жизни -- об этом мой дальнейший исторический очерк.
![]()
Числа хранятся в компьюте в ячейках памяти. Каждая ячейка небезразмерна, она способна хранить лишь фиксированное количество разрядов числа. Если уж быть совсем точным, разряды эти -- двоичные, а числа хранятся в двоичной системе, но законы здесь по большому счету такие же, что и для десятичных чисел. Большое число требует большего количества разрядов, малое -- меньшего. Ячейки же имеют фиксированный размер -- так спроектированы компьютеры. Конечно, большое число можно разбить на несколько ячеек, но тогда оно займет больше памяти, а на его обработку уйдет больше времени.
Память первых компьютеров была дорога. Баснословно дорога. Ее было мало, а машины были не очень быстрые. Поневоле приходилось экономить на всем, что касается хранения информации.
Размер (разрядность) ячеек памяти тоже был унифицирован. Это сделали с целью облегчения обмена информацией уже между компьютерами, на внутреннем уровне. Согласитесь, сложно соединить между собой 23- и 47-разрядные компьютеры. (Эти примеры не высосаны из пальца, в Советском Союзе были такие машины.)
8 бит=1 байт -- таким был установлен общий для всех моделей размер ячейки. Не много и не мало -- в самый раз для множества задач, на которые рассчитан компьютер. На этот размер и должна была опираться система кодировки символов. Ибо, повторю, компьютеры спроектированы так, что быстрее всего обрабатывают информацию в количестве, кратном разрядности ячеек. Отступление от этого правила возможно, но требует большего времени вычислений. Таким образом, на каждый символ разумно было отводить 1, 2 или более байтов.
8-разрядная ячейка способна хранить 256 чисел -- от 0 до 255. То есть, если на символ отводить минимальное количество памяти -- 1 байт, в кодировке может быть не более 256 символов. Для американцев, пионеров компьютеризации, этого было даже много. Сотни символов им хватило с лихвой. Они заняли 128 первых позиций, а вторую половину оставили свободной. Не сразу, но и стандарт единый на кодировку они у себя тоже приняли. Назывался он ASCII, и содержал все буквы латинского алфавита обоих регистров, цифры, знаки препинания и некоторые управляющие символы, вроде возврата каретки или прогона страницы. Кодировка жива до сих пор.
Западная Европа приняла ASCII за основу. Но латинского алфавита ей было мало. Для письма ей нужны буквы с надстрочными знаками, и много. Кроме того, развитие компьютеров дошло до того уровня, когда можно было потратиться на небольшое украшение изображаемого текста. Возникла потребность рисования таблиц, некоторых простейших математических символов... Короче, вторая половина ASCII тоже оказалась быстро занята. Лигатуры букв с надстрочниками, псевдографика, стрелочки, математика.
Греция, Россия. Страны, обладающие своими оригинальными алфавитами. Проблемы компьютеризации коснулись их несколько позже. Конечно, в советских ЭВМ использовался свой кодировочный стандарт, но, с поднятием "железного занавеса" и победным шествием IBM PC по постсоветскому рынку, эти стандарты не имели ни малейших шансов. ASCII была принята в качестве основы и в России. Вот только куда помещать русские буквы, ведь все 256 кодовых позиций уже заняты?
Можно расширить сам размер кодового пространства. Например, выделять на каждый символ не по одному, а по два байта. В двух байтах можно разместить число от 0 до 65535. Этого определенно должно хватить всему миру, не только России. Только вот текст будет занимать в два раза больше места. Это серьезный аргумент, но в те времена уже куда менее серьезный, чем при принятии ASCII. Еще несколько лет, и цена памяти вообще перестала бы кого-либо волновать. Те, кто принимал решение о кодировке, должны были это понимать. Нет, причина иного решения была куда более серьезной, чем дороговизна аппаратной части.
Просто к тому времени стоимость разработанного программного обеспечения давно уже многократно превысила стоимость железа. Вот попали к нам западные компьютеры. Можем мы их представить без MS-DOS, Norton Commander, MultiEdit, Turbo-C? Нет, это просто груда железа будет. Что делать? Писать свои? Да они всем западным миром десятки лет разрабатывались, причем большим штатом высокооплачиваемых программистов, на коммерческой основе. А в Советском Союзе русификацией реально занимались отдельные умельцы. Оставался один путь -- использовать готовые западные программы, переделав их по возможности под русский язык.
А западные программы все как один рассчитаны на 8-битные символы. Это жестко впаяно в алгоритмы, и без исходников неизменяемо. Да и с исходными текстами переделать программы под 16-битные символы -- проблема многолетняя. Запад ее до сих пор решает.
Поэтому у России был один практический путь: делать кодировку на основе 8-битной ASCII. И не иначе, как убрать из нее достаточное количество не очень нужных в России символов, разместив на их месте русские. Оставили на своих местах первую половину (дабы, как и во всем мире, сохранить совместимость с латиницей) и псевдографику -- дабы не переделывать готовые программы, рисующие таблицы. Точнее, выжила только та кодировка, автор которой догадался оставить псевдографику на месте. При этом ему пришлось разорвать блок русских букв, разместив их двумя отдельными диапазонами, что несколько усложняло все дальнейшие алгоритмы для работы с русскими текстами. И все же это решение оказалось удачным. Ибо в области программного обеспечения совместимость со старым важнее некоторого дополнительного усложнения нового -- до той поры, пока поддерживать старые системы становится просто невозможно. Называлась эта удачная кодировка "альтернативной", и позднее получила номер 866. Результаты же трудов отдельных НИИ -- как, например, кодировка с гордым названием "основная" -- остались только в музеях исторического софта.
Да, в России не сразу удалось выработать общий стандарт, но, к счастью, период разнобоя был здесь недолгим. Процесс сошелся, и 866 утвердилась в качестве основной и единственной. (Пока не пришел дядя Билл со своим Windows, но это уже другая история.)
Аналогично поступили Греция, Болгария и некоторые другие страны. Удалив из расширенного ASCII не очень нужные к употреблению в своей стране символы, они поместили на их места национальные.
Получилась следующая ситуация. В мире существует несколько различных кодировок -- примерно столько, сколько имеется оригинальных национальных алфавитов. Внутри каждой отдельно взятой страны кодировка единая (или процесс стремится к тому, чтобы осталась действовать только одна кодировка). Но вот между странами наблюдается примерно та же ситуация, как между Васей и Петей. Несовместимость, шифровки-кракозябры, разнобой стандартов. И, в отличие от отдельной страны, этот процесс не сходится, не стремится к уменьшению количества кодировок вплоть до единой на всех.
Ибо такой разнобой объективно продиктован следующим обстоятельством: пространства в 256 символов существенно недостаточно, чтобы уместить в пределах одной кодировки символы всех национальных алфавитов, пусть даже только Европы и только ныне живущих языков. Вместе с тем, разработчики стандартов жестко связаны величиной символа именно в 8 бит, в силу уже наработанного софта. Расширять кодовое пространство, выделяя для символов по два байта или вообще переменное их количество -- все равно, что вводить новый размер железнодорожной колеи по всему миру. Относительные затраты будут примерно такие же.
Оставался один путь. Создать несколько кодировок, по одной для каждой страны с оригинальным алфавитом. Внутри страны стандарт един, между странами -- проблемы с конвертерами, несовместимостью железа и софта, и пр.
Каждая подобная кодировка -- именно 8-битная, со своим национальным алфавитом и, как правило, с общей первой половиной кодовой таблицы -- называется кодовой страницей. Почему именно страницей, а не кодировкой, станет ясно далее, при рассмотрении Юникода. Например, кодовая страница 866 -- MS-DOS Russian, 437 -- MS-DOS United States, 864 -- Arabic, и т.д.
Это -- путь наименьшего сопротивления. Так или иначе, это была времянка. Рано или поздно давление необходимости межнационального информационного обмена должно было вынудить разработчиков ПО постепенно переходить на расширенное кодовое пространство. Впрочем, если бы только эта причина была бы двигателем прогресса, у последнего было бы куда меньше шансов начать практическую эксплуатацию нового 16-битного стандарта хотя бы к началу века.
В этот процесс вмешался еще один, очень мощный фактор. Иероглифическое письмо CJK-языковой группы. Chinese-Japanese-Korean. Представлять это письмо читателю, думаю, не надо, я лишь постараюсь дать оценку необходимого кодового пространства. Для сравнения, один из диапазонов Юникода этой группы, CJK Unified Ideographs, состоит из 20902 идущих сплошным массивом символов. Это только один (правда, самый крупный) из диапазонов, относящихся к данной языковой группе.
Никакие ухищрения с однобайтовыми кодовыми страницами здесь не помогут. И ежу понятно -- этим языкам нужно особенное, совершенно отличное от Европы решение. Беда это или счастье народа -- иметь такое письмо, но японцы с самого начала были вынуждены идти по узкому пути разработки софта "так, как надо". Способом, неприемлющим сиюминутную выгоду от быстро сданного заказа; способом, требующим основательного проектирования и несколько большего программистского труда, особенно вначале; способом, к которому Европа и Америка в конце-концов также были вынуждены прийти -- но уже в контексте необходимости переделки того, что с самого начала было сделано "не так". То есть, практически всего своего софта. К чести восточных народов, они не отказались от своего письма ради более легкой компьютеризации (хотя от компьютеров зависели намного больше России, и попытки упростить свою письменность у них имелись). Вместо этого дяде Биллу все-таки пришлось сделать дальневосточную версию Windows, со всем необходимым механизмом поддержки многосимвольных алфавитов: начиная от механизмов стандартных библиотек и операционной системы, продолжая совершенно оригинальным инструментарием ввода, и заканчивая поддержкой Microsoft Offic-ом "всего этого".
(Но да чего не сделаешь ради успешного бизнеса. Дядя Билл считать умеет, и вышеупомянутый труд своей корпорации давно уже окупил. В отличие от России, Япония платит деньги за используемый софт. Нет-нет, я вовсе не за какую-либо борьбу с пиратством, однако тотальное "обворовывание" бедняги Билла имеет и свои отрицательные последствия: на русские локализационные проблемы западному разработчику попросту глубоко наплевать -- денег-то со стороны русских все равно никто никогда не заплатит. Потому и приходится делать все самим.)
Итак, появилась насущная необходимость в создании одной общей кодировки, включающей в едином кодовом пространстве символы всех алфавитов мира. 256 символов для этого мало, и в рамках нового стандарта под каждый символ отводится по 2 байта. Доступно 65536 различных кодов. Новый стандарт получил название Unicode. Сюда попало очень многое, даже алфавиты некоторых умерших языков. И китайцы, и индейцы Чероки, и математики... Сейчас имеется уже третья версия, а в разработке находится четвертая, по слухам четырехбайтная. Кому интересно, зайдите на www.unicode.org.
Мировое сообщество все-таки пошло на столь кардинальную меру, как смена стандарта железнодорожной колеи. В генеральных планах ближайших десятилетий -- замена всех железнодорожных линий на новые; тотальная перестройка вокзальных перронов, тоннелей и депо под габариты вагонов нового образца; переориентация тяжелой индустрии на выпуск локомотивов и подвижного состава новых стандартов; и многое другое. Но это только половина проблемы. Вторая ее половина -- обеспечить на долгие годы переходного периода бесперебойное функционирование как старых, так и новых поездов, на старых и на новых линиях. Которая из двух половин сложнее -- это еще вопрос. Одно вот только ясно: подобная революция в стандартах не проходит в рамках лишь узкого круга специалистов: конструкторов, железнодорожников, путевых строителей. Она обязательно коснется поголовно каждого: всех, кто пользуется железнодорожным транспортом, прямо или косвенно. Всех, кто пользуется компьютерами -- если затрагивается основа компьютерных стандартов, размерность кодировок.
Насколько это возможно, разработчики операционных систем и приложений постараются сделать этот переход максимально прозрачным и незаметным для пользователей. Но мелкие проблемы и нестыковки все равно неизбежны. Вплоть до момента, когда старый стандарт умрет окончательно. Особенно сильно будут страдать упорные приверженцы старых систем. Если двойное увеличение ширины колеи позволит устроить в каждом купе индивидуальные душевые и туалеты, то кому от этого будет плохо? Только тем, кто принципиально продолжает ездить на старых поездах.
Далее я буду рассматривать лишь ситуацию с переходным периодом в Windows.
![]()
Со стороны прикладных программ все выглядит следующим образом. Основная ссылка, по которому приложение может обратиться к системе с просьбой нарисовать нужный символ -- это юникодный индекс символа, код символа в кодировке Unicode. Юникодный индекс есть вполне достаточный адрес, называющий именно нужный символ среди прочих шести десятков тысяч. Если приложение ссылается на символы текста по юникодным индексам -- это самый правильный и беспроблемный путь. Кракозябры в этом случае исключены -- если только само приложение поступает правильно и задает правильные вопросы, а не вынуждено реконструировать юникод-индексы из старых 8-битных текстов третьих программ; и -- это немаловажно -- если сам шрифт также сделан правильно.
В проектировании шрифтов также произошли изменения. Отныне физический порядок глифов (картинок символов) в шрифте не влияет на коды этих символов. Раньше наличие глифа с формой буквы "А" на позиции номер 65 было принципиальным, ведь 65 -- это код латинской заглавной "А" в кодировке ASCII. Теперь же буква "А" может находиться в шрифте где угодно. Вместо строгого позиционирования, каждому глифу приписываются их юникодные индексы. Именно по ним система и находит в шрифте символ, который требует приложение. Но индексы в шрифте должны быть проставлены, и проставлены правильно! В соответствии со стандартом Unicode, а не старых кодировок. То есть, русские буквы должны иметь юникод-индексы от 0410h до 044Fh, а не 00C0h-00FFh или FFC0h-FFFFh, как в старых шрифтах. Иначе система, запрашивающая русскую букву "А" с юникод-индексом 0410h, не найдет таковой в шрифте и нарисует квадратик.
Уважаемые пользователи! Не работайте, пожалуйста, со шрифтами старого формата. Зачем вам лишние проблемы? Ведь если переделка старой программы -- это действительно тяжело, то в переделке старых шрифтов ничего тяжелого нет. Вам не нужно искать с собаками производителя шрифта, не нужно с ножом у горла требовать от него переделать шрифт на новый стандарт. Чтобы преобразовать красивый, но старый TTF к новым требованиям, не нужны исходники, перекомпиляция и труды сотен программистов. Достаточно переделать в шрифте некоторые внутренние таблицы. Сохранятся и хинтовка, и кернинг -- если подходить разумно. Для многих стандартных случаев даже написаны утилиты, которые все нужное делают сами (или говорят, что шрифт какой-то ну уж очень странный). Например, всем известный ttfconv. Ну потратьте минуту, исправьте свой шрифт на новый лад сами, или попросите знакомого шрифтовика, или найдите в Интернете версию поновее -- и одной трудностью станет меньше. Оставьте у проблемы лишь одну степень свободы -- приложения.
Хорошо, а что делать с программами, которые работают или хотят работать по-старому, с 8-битными кодами символов?
Вводится понятие кодовых страниц. Кодовая страница -- это соответствие между кодовыми позициями старой 8-битной кодировки и юникодными индексами соответствующих им символов. То есть, это просто таблица из 256 элементов, где в каждой клетке на i-м месте стоит юникодный индекс символа, который в старой кодировке имеет код i. Например, в кодовой странице 1251 (Windows Cyrillic) на 192-м месте (192 -- это код русской буквы "А" в этой кодировке) находится индекс 0410h -- юникодный индекс русской заглавной "А".
Теперь, если приложение делает запрос к системе по-старому: "нарисуй символ с 8-битным кодом 192", система сама оттранслирует этот 8-битный код в юникод-индекс, опираясь на таблицы соответствия и на текущую кодовую страницу. Но! Приложение, перед тем как выводить на печать букву с кодом 192 кодовой страницы 1251, должно сообщить системе: "пока я не скажу иного, все запрашиваемые мною 8-битные коды относятся к кодовой странице 1251". Иначе система не будет знать, к какой кодовой странице относится запрашиваемый 8-битный код. Греческую ей рисовать букву или русскую. Если говорить точнее, то в случае неуказания приложением текущей кодовой страницы система считает, что выбрана страница по умолчанию. А именно, страница 1252, Windows 3.1 US (ANSI), страница, содержащая на месте русских букв те самые кракозябры, латинские буквы с диакритикой для нужд письменности Западной Европы. Именно в этом состоит основная причина появления кракозябр на месте русского текста -- в том, что приложение, их печатающее, "забыло" уточнить кодовую страницу. Либо это забыл сделать пользователь, поменявший шрифт, но не указавший кодовой страницы.
Где может быть полезен механизм указания кодовых страниц? Ведь, чтобы воспользоваться механизмом смены кодовых страниц, приложение так или иначе должно знать, что таковые надо указывать -- то есть, оно должно быть написано и откомпилировано после принятия Юникода. Но, в таком случае, не проще ли попросту переделать приложение так, чтобы оно сразу работало с 16-разрядными кодами?
Нет, не проще. Есть огромная разница с точки зрения программистского труда по переделке готового программного продукта: добавить только указание кодовых страниц при выводе (или выбор их самим пользователем), с сохранением всей остальной идеологии обработки и хранения текста нетронутыми, в рамках восьми бит; -- и полностью переделать программу на 16-битные символы.
И еще раз обращу внимание на то, что для корректной работы этого механизма шрифты должны быть сделаны по-новому. Пусть даже система и транслирует 8-битные запросы приложений -- но к шрифтам-то она обращается через юникодные индексы!
Хорошо. А что делать со старыми программами, производители которых либо давно ликвидировались, либо занимаются совсем другим, либо просто тормозят с переделкой своих продуктов? Вспомним, западные компании отнюдь не горят желанием удовлетворять нужды тех стран, от которых они не получают практически никакой прибыли. Получается, их программы смогут печатать отныне только латиницей и западноевропейскими буквами. Ведь без конкретного указания кодовой страницы по инициативе программы мы не сможем увидеть ни русских, ни греческих, ни иных символов. Американцам-то хорошо, а нам что делать?
Начать, наконец, платить бабки за установленные Форточки. Это шутка, не нервничайте :-) Есть решение попроще. В Windows можно сделать настройку следующего вида. Взять понравившийся шрифт и придумать имя шрифта, которого нет в системе, после чего указать, что если приложение пытается печатать шрифтом с придуманным именем без указания кодовой страницы, то печатать нужно символы из выбранного реального шрифта, причем с кодовой страницей -- русской (или любой другой).
Например, нам позарез нужно печатать по-русски шрифтом Times New Roman в старой программе. Придумываем имя для нового псевдошрифта: Russian Times. Сообщаем системе: если кто-то запрашивает символы из шрифта Russian Times, не ругаться по поводу его отсутствия, а выдавать символы из Times New Roman, причем с кодовой страницей по умолчанию 1251 (русская). После подобной установки во всех меню выбора шрифта появится новое имя: Russian Times. Такого шрифта физически нет, но при обращении к нему система на лету создаст виртуальный шрифт на основе Times New Roman, состоящий из 256 символов русской кодовой страницы. Для старой программы он ничем не будет отличаться от обычных шрифтов. Выбрав такой шрифт из меню, мы получаем возможность набирать по-русски в старых приложениях.
Подобные виртуальные шрифты называются кодовыми сечениями. Создавая такой псевдошрифт, мы действительно как бы делаем срез большого юникодного шрифта на уровне одной маленькой кодовой страницы.
И даже для такого механизма требуется правильный с точки зрения Юникода шрифт. Система получает запрос на печать 8-битного символа виртуальным шрифтом-сечением, отыскивает соответствующий ему реальный шрифт и кодовую страницу, транслирует 8-битный код в юникодный индекс и посылает запрос шрифту на символ с получившимся юникодным же индексом. Если шрифт сделан неправильно -- получается квадратик.
Что еще можно сказать о сечениях. Конечно, имена псевдошрифтам можно давать любые. Но имеется некоторое соглашение, на которое ориентируются многие полезные программы, среди которых есть и MS Word. Соглашение это следующее: имя сечения должно состоять из имени основного шрифта с добавлением суффикса кодовой страницы. Например, 1251 (кириллица) имеет суффикс Cyr, 1253 (греческая) -- Greek, и т.д. Таким образом, кириллическое сечение Times New Roman хорошо бы называть Times New Roman Cyr.
Некоторые сечения создаются системой сразу при установке. В русской локализации Windows -- это Cyr-сечения для шрифтов Times New Roman, Arial и Courier New -- тройки основных ttf-шрифтов системы.
У метода сечений имеется существенный недостаток: отсутствие кернинга между буквами разных страниц. Предположим, мы имеем два сечения одного и того же шрифта на разных кодовых страницах. В исходном шрифте мы можем задать кернинг между символами из разных кодовых страниц. Для шрифта все символы равноправны, для 16-битных приложений -- тоже. Но вот программы, работающие по методу сечений, воспринимают два разных сечения одного шрифта как два разных шрифта. А внешний кернинг система не поддерживает.
Поддержка кернинга между кодовыми страницами может оказаться более важной, чем это кажется на первый взгляд. Это станет ясно далее, когда будут рассматриваться различные способы представления церковно-славянского письма в электронном виде.
А как относятся к межстраничному кернингу 8-битные программы, работающие со шрифтами не через сечения, а посредством явного задания кодовых страниц при выводе? Это зависит от того, насколько глубоко программисты переделали программу. В принципе, приложению ничего не мешает отследить ситуацию, когда исходный шрифт соседних букв из двух разных страниц одинаков, и запросить у системы кернинг-пару напрямую. Но инициатива при этом должна исходить от приложения. Именно оно должно распознать подобную ситуацию и задать системе правильный вопрос. Поэтому, если переделка программы не была основательной, в приложениях данного метода кернинг между страницами тоже может отсутствовать.
Хорошо, а как обстоит дело с кернингом в 16-битных приложениях? Ведь формально здесь уже ничего не мешает приложению спрашивать у системы кернинг-пары для любых символов. Однако и тут не всегда все гладко. Виной здесь оказывается уже чрезмерная "интеллектуальность" самих приложений. Бывает, приложение помимо системы имеет некоторые внутренние знания о смысле юникодных диапазонов. Опираясь на них, оно может вообще не спрашивать систему о кернинг-парах для определенных диапазонов. Например, приложение может иметь следующее знание: "Зона CJK Unified Ideographs, содержащая иероглифы, находится там-то и там-то. Иероглифы -- письмо вертикальное, следовательно, никакого горизонтального кернинга между ними быть не может. Поэтому для данной зоны я игнорирую любую информацию о кернингах в шрифте как ошибочный мусор". Таких подводных камней встречается на удивление много.
Перед тем, как переходить к рассмотрению конкретных приложений, расскажу еще о формате RTF и об обмене форматированными текстами через буфер обмена.
Формат RTF, Rich Text Format, есть основной формат в Windows для обмена форматированными текстами (текстами со сменой шрифтов, размеров букв, с таблицами и пр.). Во-первых, любой RTF-файл обходится символами из первой половины ASCII. Во-вторых, RTF-формат спроектирован расширяемым с обратной совместимостью. То есть, если у текстовых редакторов появляются новые возможности, они могут записывать их в RTF-файл так, чтобы потом уметь однозначно восстановить. С другой стороны, старые приложения, не имеющие представления о новых возможностях, тем не менее тоже могут читать такой RTF-файл без вреда для себя, игнорируя при чтении все непонятное. Так спроектирован этот формат.
В частности, это касается и Юникода. Изначально RTF был предназначен для записи только 8-битных текстов. В RTF можно указывать и шрифт, и кодовую страницу -- причем приложения, ничего не знающие о кодовых страницах, просто пропустят этот тэг. Кроме того, в RTF можно передавать и 16-битные символы, но для совместимости со старыми приложениями для каждого 16-битного символа обязательно указывается его 8-битная замена. Если ее нет, обычно пишется знак вопроса.
В этом и кроется причина следующего синдрома: набрали текст, записали, считали в другой программе -- а там на местах букв сплошные знаки вопроса. Это означает, что вторая программа не поддерживает Юникод, а первая -- поддерживает в полном объеме.
А при чем здесь буфер обмена? Очень просто. RTF-формат -- это официально стандартный формат, посредством которого все Windows-приложения должны обмениваться форматированными текстами. Конечно, группа программ одного производителя (Microsoft Office, например), может обмениваться между собой и более эффективными, внутренними форматами. Но если приложение рассчитывает на понимание своих текстов любым другим приложением, оно обязано передать в буфер обмена наряду с другими форматами и RTF.
Следовательно, все потенциальные проблемы RTF-формата являются также и потенциальными проблемами обмена текстами через буфер.
![]()
Finale 98 и выше. Оно идет первым не из-за его распространенности, а в силу простоты ситуации. Начинать надо с легкого. Кто не знает, это навороченный нотный редактор. Нас будут интересовать подтекстовки и прочие текстовые элементы нотных партитур.
Итак, в текстовой части Finale -- это 8-битное приложение с возможностью явного указания кодовых страниц. Кодовую страницу фрагментов текста можно менять сколько угодно раз, подобно прочим атрибутам текста (шрифт, начертание, кегль и пр.).
Вот как выглядит диалоговое окно "Шрифт":
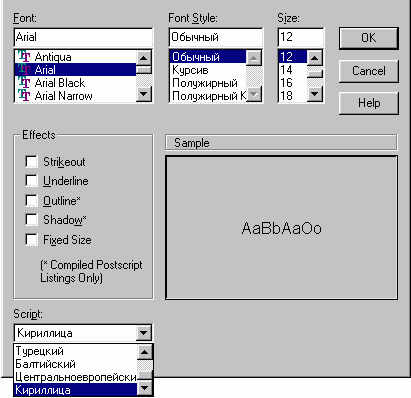
В левом нижнем углу видно выпадающее меню Script. Это и есть возможность выбора кодовой страницы.
Кернинг в Finale работает всегда, его невозможно выключить. Но вот кернинг между страницами -- не работает. По крайней мере, не работал в версии 2002 и ранее. Более того, кернинг не работает даже между двумя буквами одинаковой кодовой страницы, но набранных с их несинхронной сменой. Скажем, набрали две буквы в 1251, затем выделили одну, сменили на 1252 и снова на 1251 -- кернинг пропадет. Очевидно, Finale не умеет склеивать соседние куски с одинаковыми атрибутами, воспринимая их как набранные разными шрифтами. Помогает выделение всего куска и простановка у него единой страницы еще раз.
Finale не умеет обмениваться через буфер обмена посредством RTF-формата. Он понимает либо простой неформатированный текст, либо свой внутренний формат.
MS Word 95. Очень противоречивое приложение. Все как в известном анекдоте. "Если бы Майкрософту поручили выпуск автомобилей, Вы бы не увидели на панели управления ни уровня бензина, ни спидометра, ни температуры... Только одну кнопку "Пуск" и одну лампочку: "Общая неисправность".
Приложение это однозначно 8-битное. Судя по формируемым RTF, оно спроектировано по методу указания страниц. Но вот и на шрифтовые сечения Word 95 завязан очень сильно.
Смену кодовой страницы в Word явно произвести нельзя. Вместо этого редактор меняет ее неявно, отслеживая язык текущей раскладки клавиатуры. Но это еще не все. Редактор работает в предположении, что все шрифты с кодировкой, отличной от 1252, представлены в системе в виде сечений. Причем с именами сечений, удовлетворяющими тому соглашению, что я приводил ранее (имя основного шрифта плюс стандартный суффикс, Cyr для 1251). И если в системе присутствует сечение, по имени совпадающее с кодовой страницей языка текущей раскладки, Word меняет шрифт на данное сечение. Например, мы набирали английский текст шрифтом Times New Roman, а затем переключились на русскую раскладку и набрали русскую букву. Взглянув наверх, мы увидим, что Word самостоятельно поменял шрифт на Times New Roman Cyr. Похоже, соглашения об именах сечений просто вшиты в данный редактор.
Но и это еще не все. Word 95 настолько завязан на имена сечений, что формирует и жесткую обратную связь -- от имени сечения к кодовой странице. Вот пример. Пусть мы набираем английский текст шрифтом Book Antiqua. В системе (предположим) нет сечения Book Antiqua Cyr, хотя сам Book Antiqua -- это шрифт нового формата, он содержит под соответствующими юникодными индексами и русские, и европейские, и арабские буквы. Итак, пока мы набираем английский текст, все в порядке. Но вот мы переключились на русский язык. Word пытается найти в системе сечение Book Antiqua Cyr, не находит его -- и не переключает текущую кодовую страницу! Страница остается 1252, и мы спокойно набираем "кракозябры" вместо русских букв. Хотя сам шрифт, повторю, русские буквы содержит.
Наличие этой жесткой связи сильно портит жизнь тем, кто набирает в Word 95 тексты новыми шрифтами.
Меня могут поймать за руку сразу по нескольким поводам. Давайте разберемся.
Возражение первое. "А вот у меня есть старый испытанный шрифт, которым я спокойно набираю по-русски в Word 95". Откройте свой шрифт в любом шрифтовом редакторе и посмотрите на эти русские буквы. Скорее всего, им присвоены юникод-индексы 00C0-00FF. Это диапазон Западной Европы, а не России. Фактически Вы набираете русский текст западноевропейскими символами, только по форме выглядящими русскими буквами, а по сути -- латиницей с диакритиками. Если Вы попытаетесь экспортировать подобный текст в Word 97, всплывут две неожиданности. Во-первых, вы не сможете проверить орфографию -- ведь все буквы-то на самом деле западноевропейские, сплошные умляуты и ударения, набранные без какого-либо смысла! Во-вторых, попытавшись сменить шрифт текста со старого-проверенного на новый, Вы, наконец, увидите истину: все буквы станут кракозябрами. Точнее, они видимо станут тем, чем были все это время по сути.
Возражение второе. "А ведь в Word 95 можно набирать по-русски шрифтами Tahoma, Verdana и подобными, хотя Cyr-сечений у них нет, а сами эти шрифты -- нового формата, и русские буквы там -- это диапазон 0410-044F". Не знаю, какая распространенная программа ставит при своей установке этот патч. Загляните в win.ini. В секции [FontSubstitutes] Вы без труда найдете следующие строки: Tahoma,0=Tahoma,204; Verdana,0=Verdana,204 и похожие. Эта инструкция означает: если программа запрашивает такие шрифты в 8-битном режиме с кодовой страницей 1252, передавать ей сечения этих шрифтов с кодовой страницей 1251. То есть, в 8-битной программе мы сможем писать только русскими буквами, но не западноевропейскими. А в принципе это похоже на первый вариант. Ведь программа-то продолжает хранить текст так, как будто бы он набран западноевропейскими буквами.
Возражение третье. "А вот конвертер ttfconv превращает старые шрифты в новые, но так, что ими можно продолжать набирать в Word 95". Способ похож на второй, но только подстановка страниц происходит в самом шрифте. TtfConv всего лишь дублирует символы с юникод-индексами 00C0-00FF на символы в позициях 0410-044F. Каждая русская буква, таким образом, начинает существовать в шрифте в двух экземплярах: на правильной русской позиции и на старой, по-новому западноевропейской позиции. Фактически же в Word 95 Вы, набирая таким шрифтом русский текст, продолжаете набирать кракозябрами. Нет, это не антиреклама конвертеру шрифтов, который я сам же чуть выше посоветовал для использования. Просто здесь виновата сама прикладная программа. Но и ttfconv заслуживает своей порции критики. Я на месте разработчика удалял бы символы со старых позиций. Пусть уж некорректность набора будет видна сразу.
В свете описанной ситуации со шрифтами в Word 95, что же делать? Во-первых, не пользоваться этой версией, перейдя на более новый 97 или выше. Во-вторых, если уж очень надо -- создайте для своих любимых шрифтов Cyr-сечения, не забыв перед этим переделать в новый формат старые шрифты. Импортный модуль Word 97 корректно отслеживает ситуацию со шрифтовыми сечениями, соответствующими соглашению об именах. Поэтому такой текст будет импортирован в юникодную среду Word 97 корректно. То же касается и обмена через буфер. Впрочем, об этом далее.
По поводу межстраничного кернинга: в Word 95 он не работает. Но вот кернинг с несинхронной сменой страниц иногда работает. Word 95 умеет группировать соседние куски текста с одинаковыми свойствами. Правда, не всегда умеет отследить все случаи.
MS Word 97, 2000. Это настоящие 16-разрядные приложения. Если бы не необходимость обмена с Word 95, проблем бы не было вообще.
Word 97 и выше (в дальнейшем просто Word), за исключением некоторых специальных ситуаций, хранит текст по два байта на символ. Дальневосточная версия Word воспринимает юникодный ввод непосредственно от IME-утилит. Западная версия (в том числе и русская локализация) получает юникод-индексы, преобразуя 8-битный ввод стандартного драйвера клавиатуры Windows и информацию о языке текущей раскладки клавиатуры. То есть, если две раскладки посылают один и тот же код (228, например), но одна из них -- русская, а другая -- немецкая, то в первом случае Word преобразует код 228 в 0434 (юникод-индекс буквы "д"), а в другом -- в 00E4 (юникод-индекс "a umlaut"). Полученный юникод-индекс будет записан в виде двух байтов, и после этого уже не будет возможности как-то автоматически переделать a-umlaut в "д". В Word 95 это было бы возможно путем смены кодовой страницы (каким-то образом). Word же 97 хранит двухбайтные юникод-индексы символов, абстрагируясь от кодовых страниц, к которым они когда-то принадлежали.
Другой способ ввести какой-либо символ в Word -- воспользоваться средством из меню "Вставка/Символ...". Средство похоже на Charmap из стандартных аксессуаров Windows, но умеет больше.
Третий способ ввести произвольный символ -- воспользоваться макросами Word. Например, командой Selection.Insert ChrW (юникод_индекс). Этот способ хорош для создания надстройки-раскладчика, облегчающего ввод в какой-либо экзотичной языково-шрифтовой системе.
Множество символов, охватываемых Юникодом, больше объединения стандартных кодовых страниц Windows. Поэтому по идее Word способен хранить символы, ввести которые с клавиатуры обычным способом нельзя. Это действительно так. Западная версия Word вполне способна показать иероглифический текст. Вот только иногда Word не поддерживает полнофункциональность некоторых диапазонов вне кодовых страниц. Например, некоторые древнеславянские буквы, имеющиеся в Юникоде, но не принадлежащие ни одной кодовой странице Windows, Word может показывать, но не умеет керненгить.
Проблемы начинаются при взаимодействии Word с другими программами.
Прежде всего, импорт. Импорт 8-битных текстов из, скажем, Word 95. Только что считанный документ Word 95, вероятно, нарушает незыблемое правило юникодного Word: хранить все символы текста в 2-байтовом виде, абстрагированном от кодовых страниц. Только что импортированный 8-битный текст хранится в Word в 8-битном виде с некоторой информацией о кодовых страницах. Более того, этот текст чувствителен к смене языка. Если мы выделим участок импортированного русского текста и сменим у него язык на "Английский (США)", поменяется и кодовая страница, текст станет "кракозябрами". Обратная смена языка на "Русский" вернет букам их "русскую" форму.
Этот эффект, повторю, работает лишь на только что импортированном 8-битном тексте. Стоит данный документ перезаписать, и буквы уже навсегда становятся 2-байтовыми, не реагирующими на смену языка. Более того, даже если начать вводить русский текст посреди импортированного, вновь введенные буквы также не будут реагировать на смену языка, тогда как окружающий их "старый" текст будет меняться.
Думаю, эта возможность дана пользователю для того, чтобы иметь хоть какой-то инструмент по правке кодовых страниц только что импортированного текста.
Но основная проблема Word 97 заключается в механизме экспорта 16-битного текста в 8-битные приложения. Эта проблема возникает и при записи документа в RTF (читай -- и при передаче текста через буфер обмена), и при прямой записи документа в формате Word 95.
В чем состоит задача редукции 16-битного текста к 8-битному? Word должен взять каждый 16-битный символ текста, и подыскать для него пару: 8-битный код плюс соответствующая кодовая страница. Юникод шире объединения кодовых страниц, поэтому данная операция возможна не всегда (например, для иероглифов). В этом случае Word честно пишет на месте символа знак вопроса.
Но для европейских и российских текстов редукция, как правило, возможна всегда. Так обычно и происходит. Все русские буквы (0410-044F) Word редуцирует к кодам 192-255 и кодовой странице 1251, ну а знаки препинания с цифрами -- к 1252. Плохо другое. При редукции текста к кодовой странице, отличной от 1252, Word не только записывает идентификатор кодовой страницы, но и меняет имя сам шрифта. Шрифт меняется на стандартное сечение. То есть, для русских букв к имени шрифта принудительно добавляется суффикс Cyr. Это происходит со всеми шрифтами, а не только с теми, чье Cyr-сечение реально установлено в системе. Любые. даже самые экзотичные названия шрифтов этой участи не избегают.
Данная операция приводит к тому, что Word 95, прочитав такой экспортированный русский текст, скорее всего не сможет его показать -- если только текст не набран шрифтами TMR, Arial, Courier New или Вашими, чьи Cyr-сечения Вы самостоятельно зарегистрировали в системе. Но это пока полбеды. Вторая ее половина в том, что и иные программы, вроде PageMaker-а, тоже не найдут в системе шрифтов с суффиксами Cyr. Придется либо прописывать многочисленные шрифтовые подстановки ("Шрифт Book Antiqua Cyr считать шрифтом Book Antiqua"), либо все-таки прописать в системе Cyr-сечения всех любимых шрифтов. Это сразу решит много проблем. К сожалению, сечения для каждого шрифта нужно прописывать отдельно, а общее количество таких записей ограничено.
Кернинг в Word 97. Тяжелый вопрос, требующий исследования. Вроде бы кернинг между символами, имеющимися в стандартных кодовых страницах, работает. С другой стороны, есть примеры, когда кернинг между символами не из стандартных страниц (вроде церковно-славянских) не работает. Нужны дополнительные проверки.
MS Internet Explorer 5. Редактировать текст он не позволяет, но вот показывать -- запросто.
HTML-формат изначально был 8-битным. Более того, насколько мне известно, кодовую страницу (а точнее даже, кодировку) текста можно указать только один раз: в заголовке документа. Однако, расширения HTML позволяют передавать и смену языка, и MultiByte-текст (текст с кодами переменной длины, актуален для CJK-группы), и юникодные символы. Последние записываются в виде префикса &# и четырех 16-ричных цифр. IE в состоянии корректно показывать все это, невзирая на то, являются ли юникодные символы членами какой-либо стандартной кодовой страницы. Следовательно, его можно признать 16-битным приложением.
Кернинг в IE работает. Вот только если попытаться выделить текст с кернингом, начнутся проблемы.
Кроме того, IE также нуждается в исследовании. Например, он вполне корректно показывает символы с юникод-индексами из иероглифического диапазона. Но -- именно иероглифами. Невзирая на то, какие картинки действительно находятся в шрифте на данных местах. Неприятная новость для шрифтодизайнеров, собравшихся разместить в этом удобном диапазоне свои символьные блоки.
Adobe PageMaker 6.5. Это dtp-система. 8-битное приложение, причем без возможности явного указания кодовых страниц. Писать по-русски можно либо через сечения, либо, возможно, после вмешательства в AdobeFnt.lst. Подробнее об этом написано здесь. Межстраничный кернинг, понятное дело, работать не будет: для PageMaker два сечения -- это два разных шрифта.
Adobe InDesign. Полностью 16-разрядное приложение. Поддерживает не просто Юникод, а, по заявлению разработчиков, OpenType-возможности шрифтов. В частности, OT-лигатурную подстановку. Кернинг работает, и даже лучше, чем в Word 97-2000. InDesign почти не оглядывается на стандартные кодовые страницы. Однако, эта программа имеет свои внутренние знания о юникодных диапазонах. В частности, горизонтальный кернинг для иероглифов вертикального письма она проигнорирует.
К сожалению, для набора русскими буквами к InDesign должен быть подключен русский языковой скрипт. В стандартной поставке его нет, он докупается отдельно.